
如何快速提取Github的代码?使用LangChain的GitLoader!
2023-05-19
提取Github代码一般有两种方式:
使用 git clone 命令,直接下载到本地后复制; 直接在网页端查看 raw 文件,复制到本地。 但是,这两种方式都不够快,特别是需要 ChatGPT 来交互时,涉及大量的代码,需要更快的方式来提取 Github 代码。
这里介绍一种更快的方式,使用 langchain 的 GitLoader,快速把代码扒下来。
以下是步骤:
第一步 安装langchain库
pip install langchain
from langchain.document_loaders import GitLoader
第二步 连接Github仓库
loader = GitLoader(
clone_url = 'https://github.com/openai/openai-cookbook.git',
repo_path="Github_files",
branch='main')
data = loader.load()
代码说明:
- clone_url 是 Github 的网址,上面网址是 openai 的 cookbook,可以换成其他的 Github 网址;
- repo_path 是本地文件夹的路径,如果保持默认,即下载到当前文件夹里面的”Github_files”文档;
- branch 是 Github 的分支,一般为“mian”或者“master”。
第三步 查看文件及代码
len(data)
for doc in data:
filename = doc.metadata['file_name']
print(filename)
print(data[20].page_content)
代码说明:
- len(data)是查看文件夹里面有多少个文件,除图片外,每个文件都是一个document;
- for 循环是查看每个文件的名称;
- data[20].page_content是查看第20个文件的代码。具体数字可以自己根据文件夹里面的文件数量来调整。
彩蛋:提取.ipynb文件
很多人不知道怎么快速提取.ipynb文件的 python 代码,这里提供一个方法。
其实.ipynb文件本质上是 json 格式,我们可以先将其转为 json 格式,然后再提取代码。
刚好,openai cookbook 第20个文档是.ipynb文件,我们拿来示范一下。
首先将字符串转为 json 格式:
import json
json_file = json.loads(data[20].page_content) #将str转为json
json_file
遍历每个 cell,如果是 code 类型,就将代码提取出来:
code_cells = []
for cell in json_file['cells']:
if cell['cell_type'] == 'code':
code = ''.join(cell['source'])
code_cells.append(code)
print(code)
这样我们就可以快速提取里面所有的代码了。
如果要把代码保存为 python 文件呢?这里也提供一个方法:
# 设置保存的文件名
file_name = 'output.py'
# 将代码写入文件
with open(file_name, 'w') as f:
for code in code_cells:
f.write(code)
f.write('\n')
print(f"代码已保存到文件: {file_name}")
这样,代码就保存到了 output.py 文件里面了。
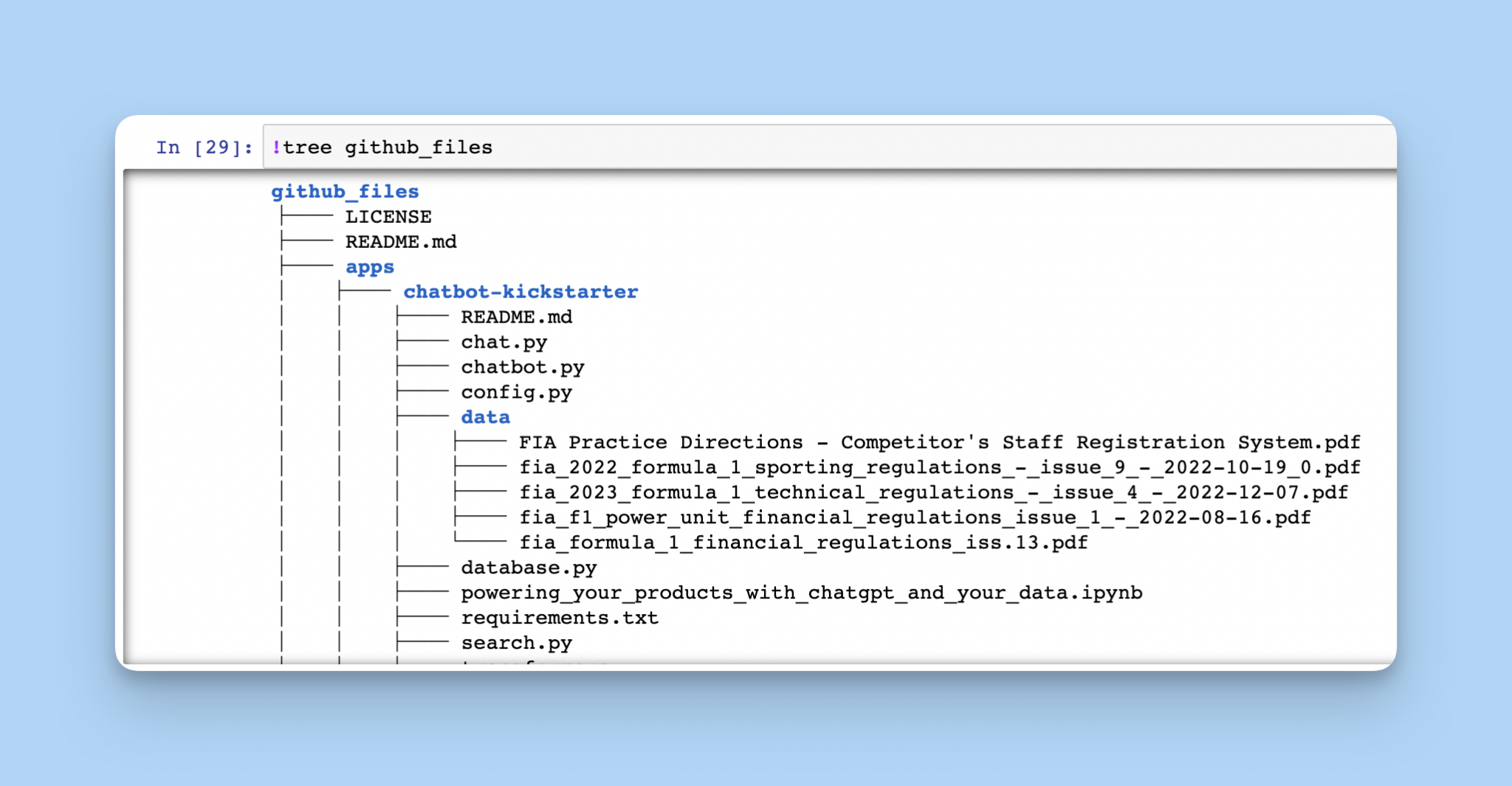
彩蛋plus:查看Github文件树
还有更直观查看 Github 文件夹的方法,那就是查看文件树。
首先安装文件树的库 tree 。以下命令需要进入命令行,用 homebrew 工具安装,如果没有 homebrew,则先安装 homebrew。
brew install tree
用 tree 命令查看:
tree github_files
效果如下:
好了,这就是如何快速提取 Github 代码的方法,希望对你有帮助。