
如何连接Pinecone向量数据库?
2023-10-07
Pinecone 控制台如图:
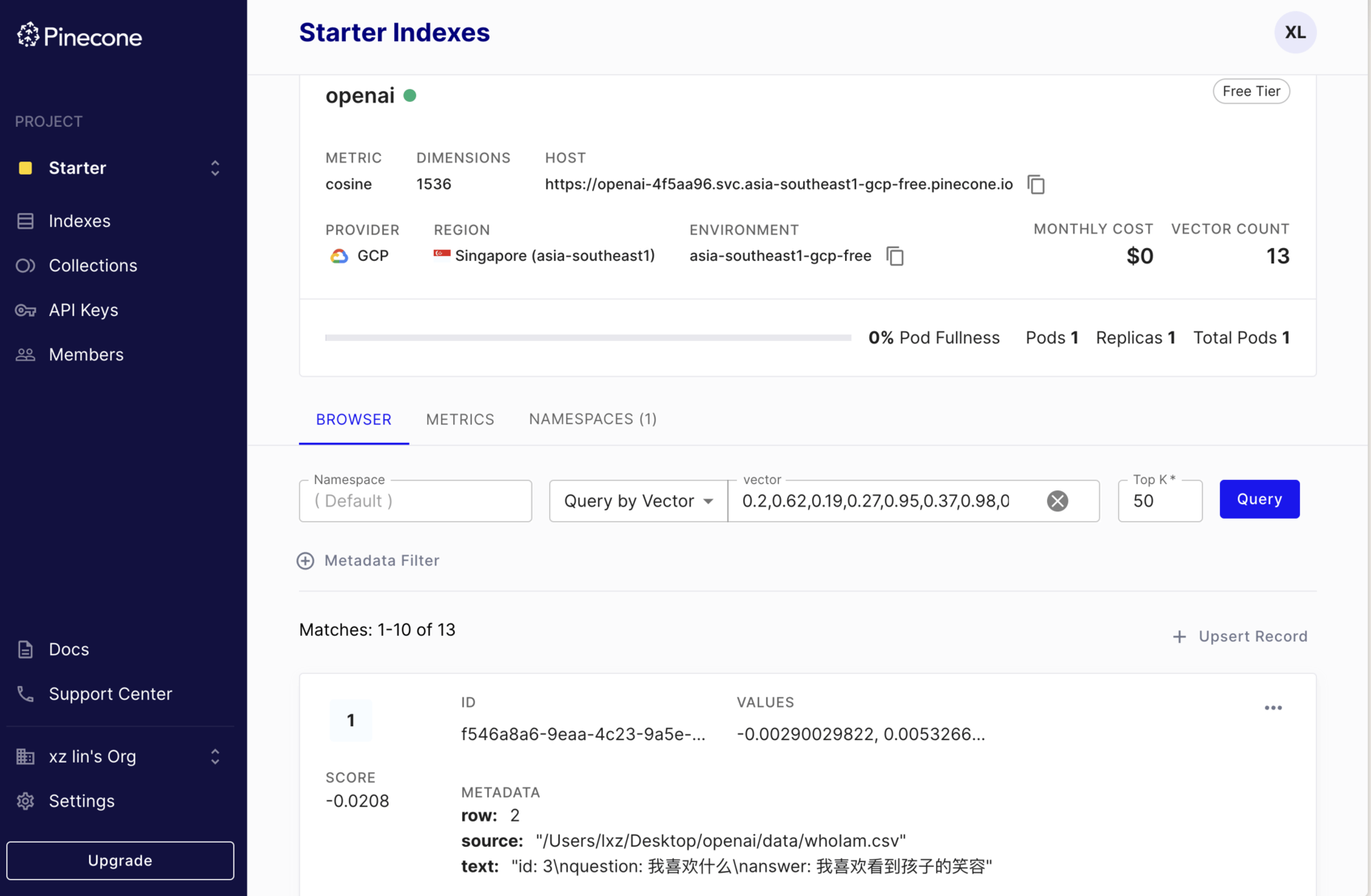
直接连接-官网推荐
1.import和设置系统变量
import os
os.environ["PINECONE_API_KEY"] = "your-pinecone-key"
os.environ["PINECONE_ENV"] = "your-pinecone-env"
!echo $PINECONE_API_KEY #看看是否能够读取
2.连接 Pinecone
import pinecone
pinecone.init(api_key=os.getenv("PINECONE_API_KEY"), environment=os.getenv("PINECONE_ENV"))
pinecone.list_indexes() #列出所有indexes,免费版的只有1个,付费至少需要$70/月
index = pinecone.Index('openai')
index.describe_index_stats()
示例结果:
{'dimension': 1536, 'index_fullness': 0.0, 'namespaces': {'': {'vector_count': 13}}, 'total_vector_count': 13}
3.读取 CSV 文件,加入 embedding 列
import pandas as pd
df = pd.read_csv('/Users/lxz/Desktop/openai/data/qa1-10.csv') #输入你的文件夹路径
df
import openai
openai.api_key = "your-api-key"
from openai.embeddings_utils import get_embedding
df['ada_v2'] = df["question"].apply(lambda x : get_embedding(x, engine = 'text-embedding-ada-002')) #给question列每一行数据都做embedding
df.to_csv("qa1-10_vectors.csv",index=False) #输出文件,不要自动加最前面一列
df = pd.read_csv('/Users/lxz/Desktop/openai/data/qa1-10_vectors.csv')
df
4.insert data to Pinecone
formatted_data = []
for _, row in df.iterrows():
# ID
entry_id = str(row['id'])
# ada_v2转为列表
ada_v2 = eval(row['ada_v2'])
# question和answer组合
text = "question: " + row['question'] + "\nanswer:" + row['answer']
formatted_data.append((entry_id, ada_v2, {"text": text}))
formatted_data #形成pinecone所需数组
index.upsert(formatted_data)
示例结果:
{'upserted_count': 10}
5.query
query = "你喜欢什么"
from openai.embeddings_utils import get_embedding
query_embed = get_embedding(query, engine = 'text-embedding-ada-002')
query_embed
result = index.query(
vector = query_embed,
top_k=3,
include_metadata=True
)
result
result_text = result['matches'][0].metadata['text'] #包含question和answer
start_idx = result_text.find('answer:') + len('answer:')
answer = result_text[start_idx:].strip()
print(answer)
通过langchain连接
1.import和设置系统变量
from langchain.embeddings.openai import OpenAIEmbeddings
os.environ["OPENAI_API_KEY"] = "your_key"
embeddings = OpenAIEmbeddings()
os.environ["PINECONE_API_KEY"]='4fece4fd-b099-48a4-89e8-284f57b32097'
os.environ["PINECONE_ENV"]='asia-southeast1-gcp-free'
from langchain.vectorstores import Pinecone
2.读取文档
from langchain.document_loaders import CSVLoader #读取csv文档
from langchain.text_splitter import CharacterTextSplitter
loader = CSVLoader('/your/path/example.csv')
documents = loader.load()
# split it into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
docs
3.连接 Pinecone
注意,提前在Pinecone后台创建 index,否则连接速度会很慢,且会连接超时。因为Pinecone后台首次创建 index 时需要较长时间。
import pinecone
# initialize pinecone
pinecone.init(
api_key=os.getenv("PINECONE_API_KEY"),
environment=os.getenv("PINECONE_ENV"),
)
index_name = "openai" #your_name
# if you already have an index, you can load it like this
docsearch = Pinecone.from_existing_index(index_name, embeddings)
query = "你是什么角色?"
result = docsearch.similarity_search(query)
print(result[0].page_content)
结语
虽然 langchain 连接看起来简单,但我最终放弃了它。原因是它的可定制性太差,而如果需要改变 class 的话,不如官网直接连接简单。