
如何做知识库检索机器人(RAG检索)
2023-10-12
什么是知识库检索?
知识库检索,又称为“检索增强生成”(RAG),是2020年MetaAI研究人员提出的概念。因为 LLM 的知识在训练之后,即变成静态的,无法适应时间的变化。
因此,更新的知识只能通过两种方法:1.重新训练模型;2.链接外部的知识库。
由于方法一既耗时又耗钱,所以我们就用方法二为主,这就是知识库检索——将外部知识库链接给LLM,让LLM来检索。
而检索效率上,又以向量检索准确度最高,所以通常辅以“向量检索”的知识。
知识库检索的一般流程如下:
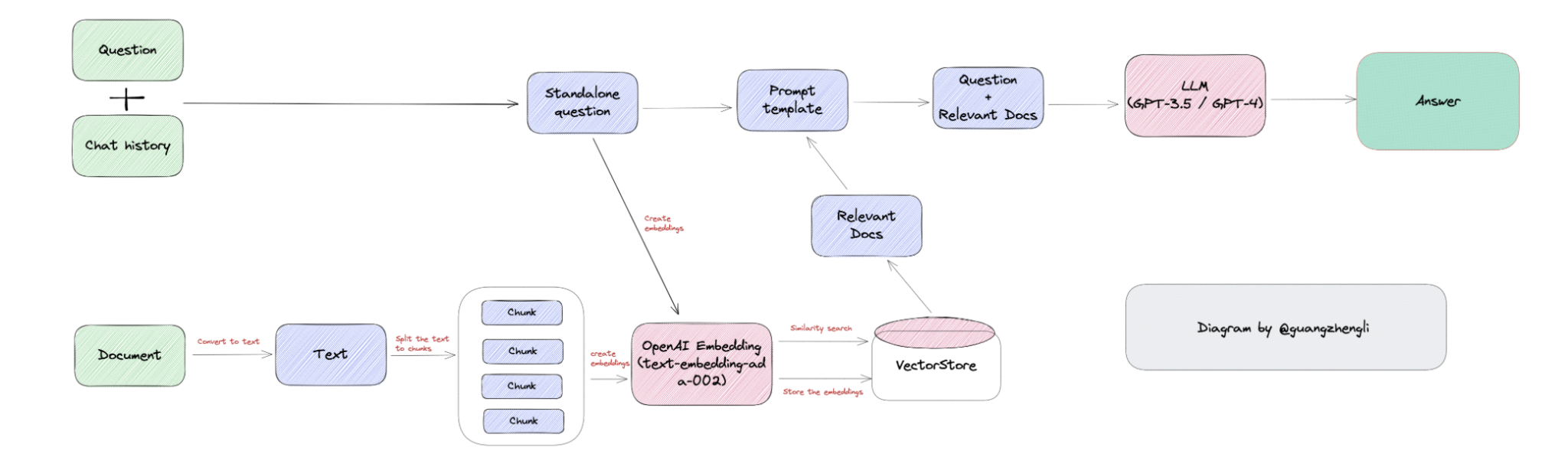
图片 by Guangzheng Li
基本步骤
1.向量存储知识
将文件(Document)的文字提出出来,分解成块(chunk),再用 embedding 模型将之存储起来,通常会存储在向量数据库中(vectore stores)。
2.向量转化问题
将用户的问题通过 embedding 模型转化为向量。
3.提取相近值
将“问题向量”和“知识库向量“做比对,通过计算找到距离最近的”知识库向量“,再把”知识库向量”里的文字提取出来。
4.LLM 过滤
由于提取出来的结果未必切题,所以把“用户问题”和“提取结果”最后提交给LLM,要求LLM以“提取结果”为参考,输出最终答案。
“过度检索”问题
如果你按照以上方法操作,或早或晚你会碰到“过度检索”的问题。什么意思?意思就是每一次你的问题,不管是否在知识库内,系统都会去检索知识库,这样又费时,效果又变差。
怎么办呢?
解决方法就是“function calling”。众所周知,我们可以通过调用函数,增强 GPT 的能力,这里也是借用它的思想——将知识库函数化,由 LLM 自己判断是否要检索知识库。
openai function calling 的文章可以参考这两篇: