
如何连接 supabase 向量数据库
2023-10-09
supabase 用的是传统的 PostgreSQL,向量数据库用的是 PostgreSQL 的扩展 pgvector。
官方连接推荐 – adapter
为什么用 adapter?因为这样就不用和向量打交道,直接用文字即可。相当于自动化文字转向量的过程。
1.import openai
import openai
openai.api_key = 'your-openai-key'
2.读取csv文件
import pandas as pd
df = pd.read_csv('/Users/lxz/Desktop/openai/data/医学数据集/短数据集/whoIam.csv')
dataset = "question:" + df['question'] + " " + "answer:" + df['answer']
3.embedding
embeddings = []
for sentence in dataset:
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=[sentence]
)
embeddings.append((sentence, response["data"][0]["embedding"], {}))
embedding的结果是一个array,里面包含许多个tuple,示例:
[('question:我是谁 answer:我是康复专家', [0.018805526196956635, -0.010052630677819252, 0.009883394464850426...],{}),....]
4.连接 vecs 数据库
import vecs
DB_CONNECTION = "postgresql://[user]:[password]@[host]:[port]/[db_name]" #Project Settings - Database - URI
# create vector store client
vx = vecs.Client(DB_CONNECTION)
# create a collection named 'sentences' with 1536 dimensional vectors (default dimension for text-embedding-ada-002)
sentences = vx.get_or_create_collection(name="sentences", dimension=1536)
5.upsert data
# upsert the embeddings into the 'sentences' collection
sentences.upsert(records=embeddings)
# create an index for the 'sentences' collection
sentences.create_index()
Indexes 可以在 Database 下找到,schema 选择 ‘vecs’;同样,table也要选 ‘vecs’。
注意,在table下面查看,会发现内容被放到id下面,如下图:
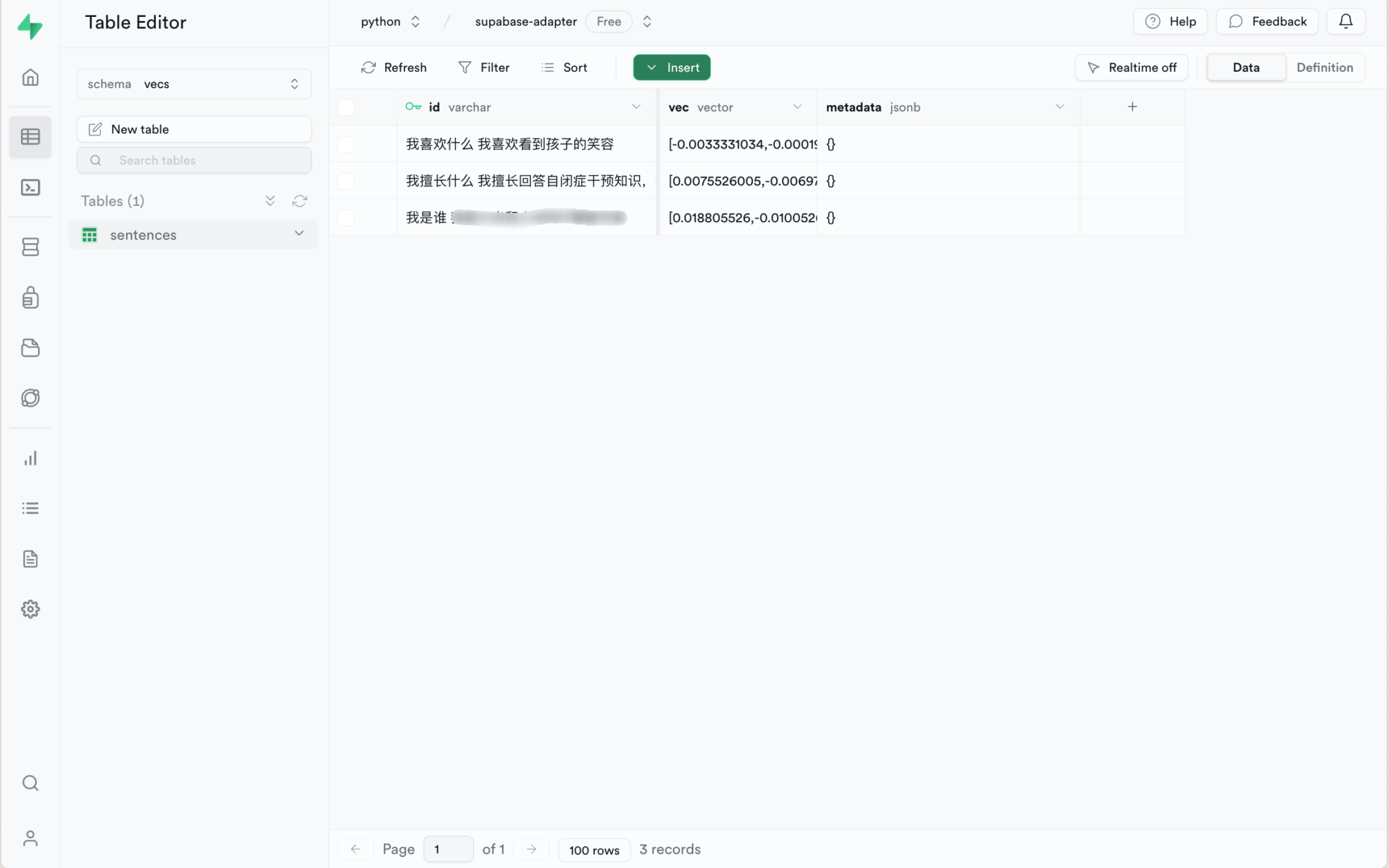
如果介意的话,可以把你的内容放入metadata,单独用一个’text’的key也行。不过,不修改也不影响效果。
6. query
query_sentence = "你擅长什么"
# create an embedding for the query sentence
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=[query_sentence]
)
query_embedding = response["data"][0]["embedding"]
# query the 'sentences' collection for the most similar sentences
results = sentences.query(
data=query_embedding,
limit=2,
include_value = True
)
# print the results
for result in results:
print(result)
返回结果示例:
('我擅长什么 我擅长回答自闭症干预知识,含发展行为、ST、OT学科的知识', 0.146888512843058) ('我喜欢什么 我喜欢看到孩子的笑容', 0.19340037048458)
因此,我们转化一下最终结果:
results[0][0]
我擅长什么 我擅长回答自闭症干预知识,含发展行为、ST、OT学科的知识
langchain 连接
1.安装库
!pip install supabase
2.连接 client
from supabase.client import Client, create_client
supabase_url = "your-url"
supabase_key = "your-key"
supabase: Client = create_client(supabase_url, supabase_key)
3.处理文件
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import SupabaseVectorStore
from langchain.document_loaders import TextLoader
from langchain.document_loaders import CSVLoader
loader = CSVLoader("/Users/lxz/Desktop/openai/data/autism_supabase.csv", encoding='GB18030')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
4.embedding
embeddings = OpenAIEmbeddings(openai_api_key="your-key")
vector_store = SupabaseVectorStore.from_documents(docs, embeddings, client=supabase)
5.query
query = "自闭症属于残疾吗?"
matched_docs = vector_store.similarity_search(query)
print(matched_docs[0].page_content)
示例结果:
question: 医生,您好.我于今年3月早产(孕34周破水急产,造成宝宝重度缺氧缺血性脑病夭折),是顺产.现在时隔三个月发现又怀孕了,请问我能顺利要这个宝宝吗?这次还会不会再发生早产呢?我要注意什么呢? answer: 你好原则上是需要至少是避孕半年的,现在既然是怀孕了可以保留和定期的孕检如果知道第一次异常的原因现在进行治疗和预防为好。 chunk_number: 1
6.结果处理
k = matched_docs[0].page_content
import re
match = re.search(r'answer: (.*?)\n', k)
if match:
answer = match.group(1)
print(answer)
else:
print("答案未找到")
示例结果:
你好原则上是需要至少是避孕半年的,现在既然是怀孕了可以保留和定期的孕检如果知道第一次异常的原因现在进行治疗和预防为好。
结语
相对来说,langchain 的方式更简单,但自由度较低。我在生产环境测试(即连上云服务器),发现langchain 的 supabase 无法工作,总是提示少了某个模块,而本地开发环境则没问题。所以,不推荐在生产环境使用 langchain 来连接。